

Picture this: It’s Monday morning. Your CFO opens a revenue dashboard and sees $4.2 million. The sales director’s report, pulled from a different system, shows $3.8 million. Marketing claims $5.1 million based on their campaign files. Meanwhile, the data engineering team is already in a war room trying to reconcile three different ETL jobs that ran over the weekend. Analysts are stuck waiting for a ticket to be approved so they can get “read access” to yesterday’s logs. Security just flagged another shadow copy of customer data sitting in someone’s personal OneDrive.
Sound familiar? This isn’t a hypothetical nightmare it’s the daily reality for most enterprises in 2026. Data lives everywhere, in every format, under every team’s control. The result? Confusion, wasted time, duplicated effort, compliance headaches, and decisions made on shaky foundations.
Microsoft Fabric Lakehouse was built to end this chaos once and for all. It doesn’t just move data around it unifies every single byte of your organization’s data into one governed, high-performance, open-format environment. Structured tables, raw logs, JSON events, images, streaming telemetry, and even tomorrow’s AI training datasets all live together under one security model, one governance framework, and one query engine.
No more silos. No more brittle sync pipelines. No more “which version of the truth are we using today?” Fabric Lakehouse delivers the simplicity of a data lake, the reliability and performance of a data warehouse, and the openness required for the AI-first future all in a platform that scales effortlessly from pilot to enterprise.
What a Lakehouse Actually Is
For years, organizations faced an impossible choice:
- Data Warehouses (think traditional SQL Server, Snowflake, or Redshift): Excellent for structured data, ACID transactions, and fast SQL queries. But they completely reject unstructured files, logs, images, or high-velocity streaming data. Trying to force everything into rigid tables creates massive ETL overhead and kills flexibility.
- Data Lakes (Azure Data Lake, S3, etc.): They accept anything any file type, any volume and scale to petabytes without breaking a sweat. The problem? They quickly turn into data swamps. No governance, no schema enforcement, poor query performance, and zero transactional safety. Finding anything reliable becomes a full-time job.
In a Fabric Lakehouse you get:
- Structured Delta tables and raw files co-existing peacefully in the same logical container
- Instant SQL or Spark access to everything — no data movement required
- Enterprise-grade security, lineage, and governance applied uniformly across all assets
- Seamless connectivity for any analytics or AI tool (Power BI, Excel, Databricks, Python notebooks, custom applications)
- Automatic performance optimization that keeps getting smarter over time
The Fabric Lakehouse Architecture That Feels Like Magic
Everything in Fabric sits on top of One Lake Microsoft’s breakthrough unified storage layer. One Lake acts as the single source of truth for every workload in Fabric, when you create a Lakehouse, 3 perfectly synchronized components spin up instantly:
1. The Files Section
This is where raw data first lands. You can drop in CSV, Parquet, JSON, Avro, ORC, files, logs literally anything. You organize folders exactly the way your business thinks (by department, by date, by source system). Behind the scenes, Fabric quietly converts every file into the open Delta Lake format. This gives you ACID transactions, time travel, schema enforcement, and versioning automatically features that traditional data lakes have always struggled to deliver.
2. The Tables Section
Here’s where the real magic happens. As soon as data lands in Files (or is transformed), Fabric automatically surfaces it as queryable Delta tables. No manual CREATE TABLE statements. No complex schema-on-write ETL. The moment a file is written in the right format, it becomes a live table that Power BI, Spark, and the SQL endpoint can all see simultaneously. Engineers transform once; everyone else benefits forever.
3. The SQL Analytics Endpoint
The instant your Lakehouse is created, a fully managed, serverless SQL engine is provisioned and ready. Analysts can connect Excel, Power BI, Azure Data Studio, or any BI tool with a simple connection string. No clusters to spin up. No capacity to manage. Just enterprise-grade SQL performance on top of your open Delta tables.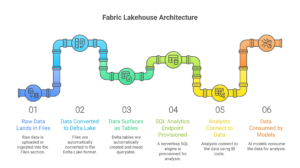
The entire data journey becomes almost simple: Raw data → lands in Files (via upload, pipeline, or shortcut) Engineers clean and enrich it once → Tables section Analysts, executives, and AI models consume it immediately through SQL, Spark, or Power BI.
Why Lakehouse’s?
A Fabric Lakehouse doesn’t just solve today’s problems it positions your organization for the next decade of data and AI innovation.
Single Source of Truth
Everyone from finance, sales, marketing, operations work from the exact same governed data. Conflicting reports become a thing of the past. Trust returns to your analytics.
True Openness & Zero Vendor Lock-In
Every table is built on Apache Parquet and Delta Lake open standards. If you ever decide to move tools or even clouds, your data remains portable. No expensive migration projects. No rewriting decades of pipelines.
Enterprise Governance at Scale
Set permissions at workspace, lakehouse, folder, table, row, or even column level. Track end-to-end lineage from source system to final dashboard. Audit every single access for compliance (GDPR, SOC2, HIPAA, you name it). Everything lives in one pane of glass.
Performance That Improves by Itself
Delta Lake’s automatic compaction, optimized writes, and background statistics collection mean your queries get faster over time without anyone lifting a finger. Small files are merged, indexes are maintained, and caching is handled intelligently.
Built-in Version Control for Data
Need to see what a table looked like last Tuesday? Query it with a simple AS OF timestamp. Made a bad transformation? Roll back in seconds. No more “restore from backup” panic at 2 a.m.
Any Tool, Any Language, Any Team
The same table can be queried with pure T-SQL by analysts, PySpark by data scientists, R by statisticians, or directly in Power BI visuals. Changes appear everywhere instantly. Collaboration becomes frictionless.
Creating Your First Lakehouse under 60sec
The best part? Getting started requires zero infrastructure planning.
- Go to fabric.microsoft.com and open (or create) your workspace.
- Click + New → Lakehouse.
- Give it a business-meaningful name. Names that actually tell people what lives inside.
- Click Create.
In seconds you’ll see the clean Files and Tables sections, the SQL Analytics Endpoint is already live, and you have a fully functional Lakehouse ready for data.
Loading Data: Choose the Right Method for Every Use Case
Fabric gives you multiple paths pick the one that matches your data velocity, volume, and team skill level.
Direct Upload Perfect for quick tests or small one-time loads. Just drag CSV, Excel, JSON, or Parquet files straight into the Files section.
Data Pipelines Enterprise-grade orchestration. Connect on-premises SQL Server, Azure SQL, cloud storage, REST APIs, file shares anything. Schedule hourly, daily, event-driven, or on-demand. Built-in retry logic, detailed monitoring, and error handling included.
Spark Notebooks Full programmatic control using PySpark, Spark SQL, or Scala. Ideal for complex transformations, machine learning feature engineering, or scheduled production jobs.
Dataflows Gen2 No-code, low-code experience designed for citizen developers and business analysts. Point-and-click connectors with powerful transformation capabilities.
Shortcuts The Gamechanger This is where Fabric truly shines. Create a shortcut to data already sitting in One Lake, Azure Data Lake Storage, or even S3. The data never moves — it’s queried in place. Storage costs drop dramatically, duplication disappears, and governance stays centralized.
Connecting to Common Enterprise Sources
- SQL Databases: Full refresh or incremental loads via pipelines using SQL authentication or managed identity.
- Cloud Storage: Use shortcuts for frequently changing files or pipelines for archival data.
- REST APIs & SaaS Applications: Notebooks pull JSON, parse it intelligently, and land clean Delta tables.
- Real-Time Streams: Connect Event Hubs, IoT Hub, Kafka, or streaming services. Data becomes query able within seconds of arrival perfect for operational dashboards and real-time AI.
- On-Premises Systems: Secure pipelines with Data Gateway handle legacy mainframes, file shares, and ERP systems.
What Happens the Moment Your Data Lands
Your Lakehouse instantly becomes the trusted foundation for the entire analytics and AI ecosystem:
- Business users build live Power BI dashboards that refresh automatically
- Data scientists run Spark transformations on the exact same tables used for reporting
- Security teams apply row-level and column-level security once
- Engineers create reusable views and star schemas directly on Delta tables
- AI and ML models train on governed, versioned data without additional pipelines
One security model. One governance framework. One reliable source of truth for every team and every use case.
The Measurable Business Impact Organizations Are Seeing Today
Companies that have migrated to Fabric Lakehouse consistently report dramatic improvements:
- Elimination of multiple overlapping warehouses and lakes
- End of fragile, high-maintenance cross-system synchronization pipelines
- 70–90% reduction in data movement and duplication overhead
- Single location for all compliance, lineage, and access auditing
- Significantly lower total cost of ownership through storage consolidation and automatic optimization
Ready to Stop Fighting Your Data and Start Winning With It?
The era of scattered, siloed, painful data platforms is officially over. Microsoft Fabric Lakehouse gives you the best of data lakes and data warehouses, delivered in an open, governed, AI-ready platform that requires almost zero infrastructure management.



